

As a machine learning engineer, AdaBoost is one hell of an algorithm to have in your arsenal. It is based on boosting ensemble technique and is widely used in the machine-learning world. Before we dive deep into this article, you should have a basic idea about the Decision Tree and Random Forest algorithm.
Let’s get started

- The basic concept behind AdaBoost is that multiple weak learners can work together and give better performance.
- In random forest, the depth of the tree was not predefined but in AdaBoost, we make use of stumps which are trees having only two leaf nodes.
- These stumps are technically called “Weak Learners”.
- The collection of many weak learners makes the AdaBoost Algorithm.
Comparison with Random Forest
- In a random forest, all the trees created were independent of each other, whereas in AdaBoost the misclassified examples in one stump decide the input data for the other stump.
- In a random forest, the depth of the tree is not predefined, whereas in AdaBoost the depth is restricted to only two leaf nodes per stump.
- In random forest, each tree has an equal say in classification, whereas in AdaBoost some stumps may have a higher say in classification.
Let’s Dive into the algorithm

- Let’s take the Iris dataset as an example. This dataset contains 4 features namely Sepal length, Sepal width, Petal Length, and Petal width, and then we have 4 target classes(Species).
- We assign a sample weight(Sample Wt.) to each example and initially, this weight is set to 1/n (n=number of examples).
- Now we create a stump using each column and then choose the best one using Gini Index for each feature.
- Now we need to decide how much say this stump will have in classification. The amount of say will be based on how well the stump classifies examples.
- We calculate the total error for the stump which is given by the sum of sample weights of the total number of misclassified examples. Suppose our dataset consists of 100 examples and our stump misclassified 10 of them. In this case, the Total Error for the stump will be (1/100) * 10. (1/100) is our initial sample weight of each example.
- Now we calculate the amount of say for the stump which is given by the following formula:
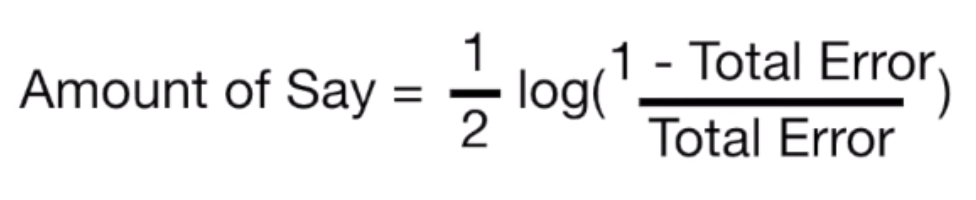
- Let’s have a look at the graph between the amount of say V/S Total Error, to get a better idea of things

- From the above graph we can see that if the total error of stump is low, it will have a higher amount of say and vice versa.
- Now we emphasize classifying the samples which were incorrectly classified by the initial stump. We do this by updating the Sample Wt. of each example.
- For the correctly classified example, the weights are updated as:

- For examples that were incorrectly classified, their sample weight is updated using the formula:

- Now we can see that the updated weights for correctly classified examples are lower than that of incorrectly classified examples.
- After this, we normalize the updated sample weights such that their sum is equal to 1.
- Now we create a new dataset using the old one such that it contains more examples that were misclassified by stump 1. This can be done using the updated sample weight since incorrectly classified examples will have higher weights.
- Since we have a new dataset, we repeat the above process until we get multiple stumps.
How does Adaboost make predictions?
- You come with an example and you pass that example through all the stumps that we have created.
- Now out of 6 stumps suppose 3 classified it as belonging to class A and 3 classified it as class B. Oh No, it’s a tie. Don’t worry we don’t follow aggregation here as we did in random forest.
- Remember we calculated the amount of say for each stump. Yes, that will come into the picture now. We sum up the amount of say for stumps predicting A and the sum of the amount of say for stumps predicting B. Then whichever sum is higher will be the winner and those stumps will classify our example.
Hope you got a basic understanding of AdaBoost.
Till Then Happy Learning!!