
We all have heard about neural networks and how it is able to learn any complex function. But let me tell you it’s no real magic rather a combination of some cool algorithms and theorems put together such that they manage to replicate human level accuracy.
In this article we’ll go layer by layer and understand what’s going on behind the scenes.
Problem Statement
Let’s take a problem statement for binary classification. Suppose you are given a dataset in which you are given some features and based on those features you have to tell whether a person has cancer (class 1) or not (class 0).

Task
Now our task is to find a function which can map our features to our class, i.e. we input our features in the function and it should give us the class. Let’s plot and see our data and what function can help us.

In the above plot we can see that our data is not linearly separable i.e. y = w1*x +b won’t help much. That’s why we introduce non-linearity using sigmoid function which is given by

When we pass our data through this sigmoid function we get a curve similar to one in the above graph and we can tune the shape of the sigmoid function using hyperparameter tuning i.e. by adjusting the value of weights and biases( w and b in the equation y = w*x + b respectively).
Reality Hits
But is it really that simple that by seeing the data we can tell what function will help us? Actually, in real world problem the data that we see is much more complex with lots of features and classes and even more complex is to predict the function to be used to separate them in classes. Let’s have a look at some data and see why we need neural networks.

Just by looking at the above plot we can’t tell which function may help us and how do we get some zigzag function which can separate the two classes.
Now what to do?
Neural Networks to rescue

So neural network is nothing, but a network of neurons and each neuron tries to learn a simple function and with the help of these simple neurons, the network tries to learn a very complex function.
In the above image we can see there are 4 input features(Input layers) and each input is passed through each of the neurons in the hidden layers, whose output is passed on the following layer and finally we have an output layer with 3 output neuron(i.e. 3 classes).
Now the world already knows the power of neural network and how good they are in learning these complex functions, but what actually is happening inside these networks and why are they so good. The answer is complex yet very simple.
Universal Approximation Theorem
According to Wikipedia
In the mathematical theory of artificial neural networks, universal approximation theorems are results that establish the density of an algorithmically generated class of functions within a given function space of interest. Typically, these results concern the approximation capabilities of the feedforward architecture on the space of continuous functions between two Euclidean spaces, and the approximation is with respect to the compact convergence topology.
It took me around two days to get my head around the above definition. So now, let’s try to understand it with a story.
Suppose you are a mason (Just imagine it), and you are given a task of building a house.
Now, since you are a senior mason you have a team of your own. Now what you do is rather than focusing on the house, you divide the task to build the house into smaller subtasks like laying the foundation, building walls, building the roofs and the smallest one being laying bricks and now based on house design you can modify these simple subtasks.
You must be thinking how this mason story help me demystify neural networks, but that’s what neural networks are doing.
Let’s get this with a plot
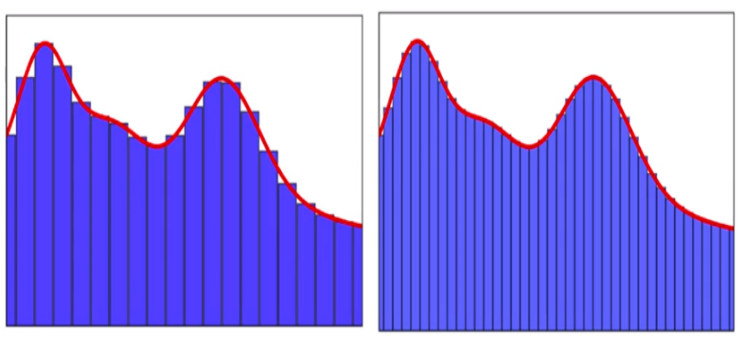
We know we can’t tell what the suitable function is to plot the graph in red (Fig. 4) since that is very complex (like our house). But we know how to plot the bar graphs and we can try to adjust the height and width of these bar graphs so that they pretty much close to our actual function. And we can also see that by increasing the number of bar graphs we are able to approximate more (That doesn’t work every time).
Now the next question arises how we get these bar graphs. Let’s see

Remember we had a sigmoid function, and we can adjust it shape by tuning weights and biases. In the above image, we have a single feature, now we pass this feature through 2 neurons (each having their own weights and biases) and get a sigmoid graph for each of these neurons with little bit different shape. In the final layer we pass the output of these two neurons into another neuron (which combines the result of these two neurons) which gives a little bit more complex function. Now rather than having 2 neurons and a single layer, if we have more layers and more neurons in each layers then we’ll be able to approximate the required function more closely, and this is the basis of how Universal Approximation Theorem acts behind the scene.
There are some more things you can try and explore on your own which are out of scope of this article.
1) Apart from sigmoid what all activation functions can be used?
2) How do we know what weights and biases to use for each neuron?
3) How do we know how close we are to the required function?